Willkommen! OpenRuhr ist eine offene Plattform für mehr OpenData und OpenGoverment im Ruhrgebiet. Mehr Infos, das Ratsinformationssysten-Projekt, Newsletter, Kontakt.
Hervorgehobener Beitrag
Willkommen! OpenRuhr ist eine offene Plattform für mehr OpenData und OpenGoverment im Ruhrgebiet. Mehr Infos, das Ratsinformationssysten-Projekt, Newsletter, Kontakt.
Die Stadt Essen ist nun auch auf Wo ist Markt? vertreten:
https://wo-ist-markt.de/#essen
Dieses Projekt visualisiert auf einer Karte, wo gerade Wochenmarkt ist. Man kann für den aktuellen Tag filtern oder sich alle Märkte einer Stadt anzeigen lassen. Die gerade stattfindenden Märkte werden grün gekennzeichnet.
Die Karte ist dazu auch mobil auf dem Smartphone nutzbar und somit ist es praktisch, wenn du unterwegs bist und schauen möchtest, ob in deiner Nähe gerade ein Markt stattfindet.
In den letzten Monaten hat sich so einiges entwickelt. Ihr habt sicherlich schon einmal von Code for Germany gehört. Noch nicht? Überhaupt nicht schlimm, einfach hier klicken.
Und es gibt sogar schon ein erstes großes Treffen! Wir werden uns zusammen mit dem OK Lab Niederrhein am 05.03.2016 zum Open Data Day im Unperfekthaus in Essen treffen. Alle wichtigen Infos findet ihr bereits auf Meetup.
Aber das wichtigste ist jetzt, dass ihr euch so schnell wie möglich in unsere Mailingliste eintragt. Damit wollen wir unser erstes richtiges Kommunikationsmedium aufbauen.
Alle weitere Ideen wie einen Slack-Channel oder etwas ähnliches können wir dann darin besprechen.
Die wichtigste Seite ist unsere Unterseite auf der Code for Germany Webseite. Die erreicht ihr über den folgenden Link:
↳ http://codefor.de/ruhrgebiet/
Dort sind dann auch alle relevanten Termine, sowie unser Etherpad und Profile gelistet. Und wenn du dich jetzt immer noch nicht in unsere Mailingliste eingetragen hast, dann findest du den Link da natürlich auch nochmal!
Damit wir aber mit tollen Projekten unser erstes Jahr meistern können, müssten wir noch ein paar Schwerpunkte für unser Lab in diesem Jahr festlegen. Wenn euch also etwas am Herzen liegt oder ihr einfach einen Vorschlag in die Runde werfen wollt, dann schreibt das direkt in die Mailingliste (traut euch!). Wenn es nur kleine Projektideen sind, dann können die auch erst einmal in unser Etherpad geschrieben werden.
Alles weitere wird in den nächsten Tagen und Wochen auf euch zukommen.
Das geht aber nur mit eurer Hilfe! Wenn du also Lust darauf hast etwas zu verändern und der Welt zu zeigen, was wir alles mit offenen Daten bauen können, dann komm einfach auf uns zu!
Und wenn es die kleinste und am schnellsten umgesetzte Idee ist, die unsere Gesellschaft aufweckt: her damit!
Naa, freut ihr euch darauf? Lasst uns direkt loslegen!
Martin
Am 5.3. ist wieder einmal OpenDataDay. Dieses mal kommt er direkt in die Region: gemeinsam möchten OpenRuhr (oder auch OK Lab Ruhr) und OK Lab Niederrhein spannende Apps und Projekte entwickeln. Ab 11:00 bis etwa 19 Uhr werden sich eine Reihe an Menschen aus der Region im Unperfekthaus treffen und programmieren, reden, zeichnen, planen und schreiben.
Herzlich eingeladen sind nicht nur die “alten Hasen”, sondern insbesondere auch Menschen, die bislang wenig mit OpenData zu tun hatten. Man muss kein Programmierer sein, um etwas spannendes mit Daten zu machen – egal, ob Texter, Grafiker, Politiker, Designer, Journalist, Datenanalyst oder eben Programmier, fast jeder kann einen Teil dazu beitragen, aus Daten wertvolle Anwendungen für die Zivilgesellschaft zu bauen.
Wir freuen uns auf Eure Teilnahme! Bitte meldet euch bei dem Meetup an, welches das OK Lab Niederrhein erstellt hat, damit wir eine Zahl abschätzen können.
Und noch ein Hinweis: es kostet 6,90 €, um in das Unperfekthaus zu gelangen. Dafür gibt es dann eine Getränke-Flatrate, Internet und vieles mehr.
Am 4. und 5. Dezember wird im bei uns im Labor in Bochum der erste OpenRuhr Hackathon stattfinden.
Die OpenSource-Software des Portals “politik-bei-uns.de” nimmt vorhandene Informationen aus dem Ratsinformationssystemen einiger Kommunen, darunter Bochum, Köln und Moers und macht diese durchsuchbar und setzt sie in Gesamtkontexte.
Es soll der Funktionsumfang des “Scrapers” (Programmteil, der die Informationen aus dem kommunalen Ratsinformationssystemen holt) erweitert und zudem die Bedienbarkeit und Übersichtlichkeit des Webinterfaces verbessert werden.
Dies ist aber bei weitem nicht alles. Wir wollen zusammen mit den Hackathonteilnehmer darüber beraten, in welche Richtung man mit den vorhandenen Daten und dem gesamten OpenSource-Projekt gehen könnte und welche anderen OpenData-Anwendungen für das Ruhrgebiet denkbar wären.
Die Software ist in Python 2.7 geschrieben und verwendet als Web-Framework “Flask”. Wer sich also im Bereich Webentwicklung auskennt, kann sich gerne beteiligen. Wir bieten auch am 4. Dezember eine kleine Einführung in Flask und die Struktur des Projekts des “Offenen Ratsinformationssystems”.
Zudem benötigen wir natürlich Beta-Tester und Ideengeber für APIs (Schnittstellen), das Interface und grundsätzliche Funktionalität und Wartbarkeit. Wer also nicht Programmieren kann, darf die Software auf Herz und Nieren prüfen oder sich wie jeder andere an der Diskussion um neue Funktionen beteiligen.
Wer zudem Fremdsprachen beherrscht, kann gerne bei der Übersetzung der Software helfen, damit noch mehr Menschen davon profitieren.
Fr, 4. Dezember, ab 17:00 Uhr
Sa, 5. Dezember, ab 12:00 Uhr
Location
Das Labor e.V.
Alleestraße 50
44793 Bochum
Ansprechpartner
Dennis (Mail) und Ernesto (Mail, Website, Twitter)
Weitere Informationen
Im Zusammenhang mit dem OpenData-Projekt “Offenes Ratsinformationssystem” müssen viele Daten von offiziellen Stadt-Websites abgegriffen und verarbeitet werden. Mit diesem Blogpost möchte ich einen kleinen Blick in den Maschinenraum werfen und zeigen, wo die Daten “entlangfließen”.
Wenn man Daten verarbeiten möchte, so möchte man am liebsten eine Schnittstelle haben. Eine Schnittstelle stellt Daten strukturiert bereit. Strukturierte Daten sind an sich nicht besonders hübsch lesbar für das menschliche Auge, aber um so besser geeignet für die maschinelle Verarbeitung. Formate dazu wären JSON, XML oder (notfalls) auch CSV. Marian Steinbach hat daher die JSON-Schnittstelle OParl für Ratsinformationssysteme entwickelt. An dieser Schnittstelle kann man auch ein zweites wichtiges Feature einer Schnittstelle erkennen: Dokumentation. Der Programmierer muss wissen, was für Daten ihn erwarten.
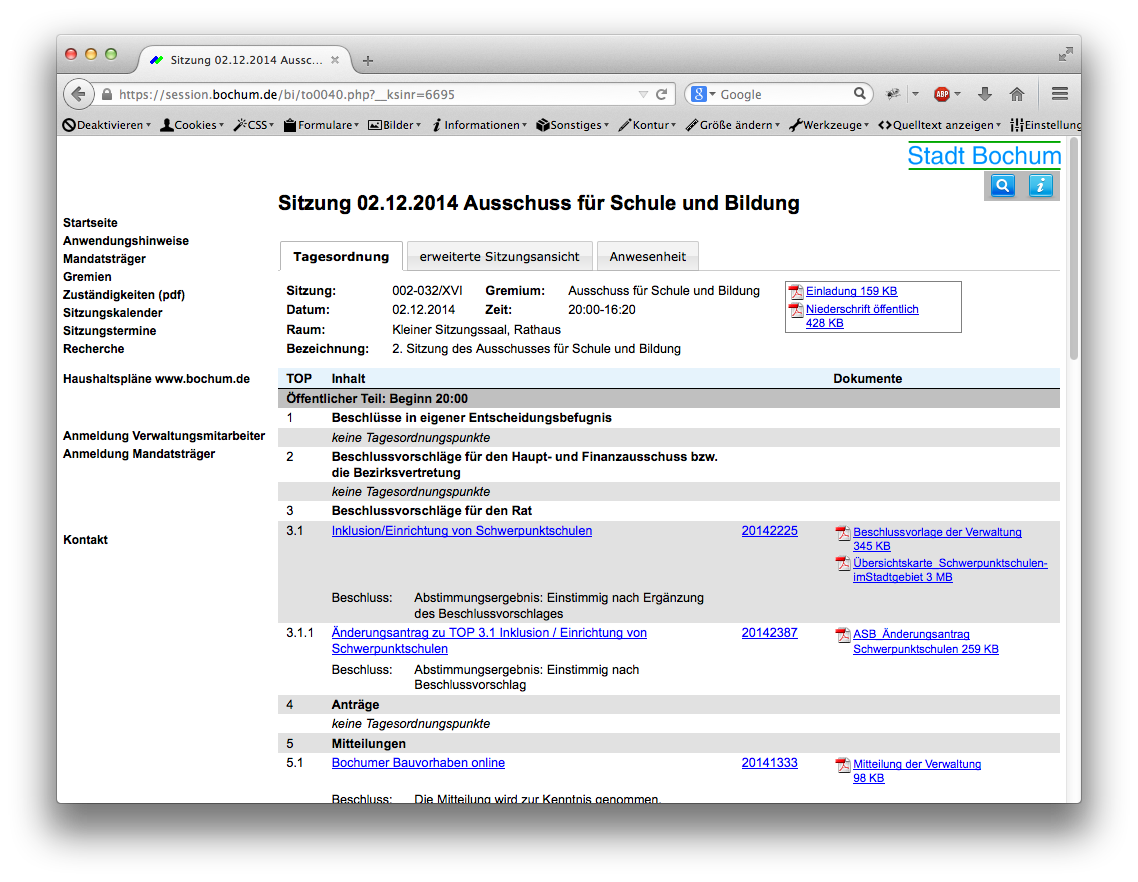
Die grafische Oberfläche eines Ratsinformationssystems
Die aktuell auf dem Markt befindlichen Ratsinformationssysteme bieten öffentlich bislang ausschließlich die HTML-Ausgabe. HTML stellt im Idealfall Informationen ebenso strukturiert dar – schließlich ist HTML im Endeffekt auch nur ein XML Dialekt. Die Realität sieht leider anders aus: Die Ausgabe versucht ausschließlich, dem Nutzer mit seinem Webbrowser die Informationen darzustellen – visuell irgendwie sinnvoll, aber nicht strukturiert. Üblicherweise wird auch noch das deutlich veraltete HTML 4.01 verwendet, was um so weniger Möglichkeiten der Struktur bietet, und selbst diese Möglichkeiten werden nicht genutzt.
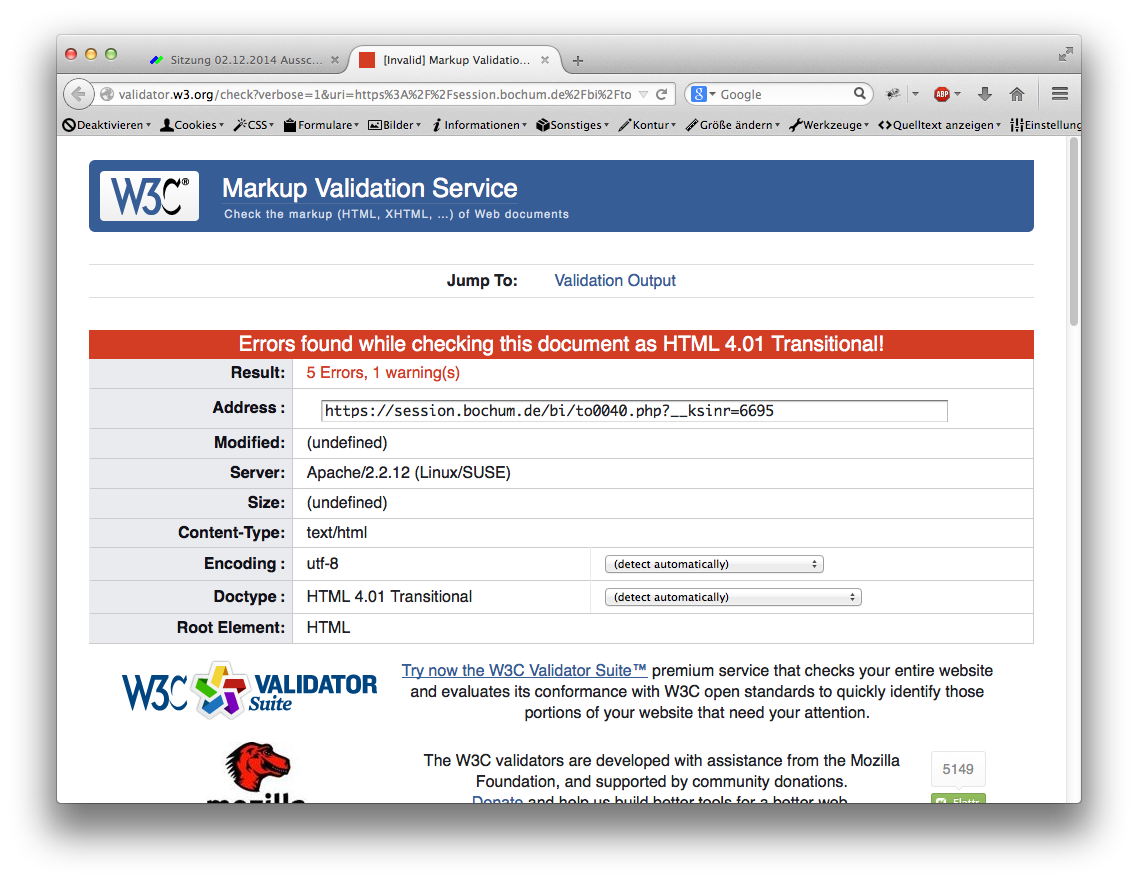
Typische HTML-Fehler in einem Ratsinformationssystem.
Der mühsamste Ansatz ist, durch die visuelle Ausgabe zu springen und die einzelnen Informationen herauszugreifen. Dafür nutzt man aus, dass die Ratsinformationssysteme IDs und Klassen nutzen, um die HTML-Ausgabe zu layouten. Diese IDs und Klassen bieten oft (aber leider nicht immer) eindeutige Pfade zu der Position der gewünschten Information. Dieser Pfad wird CSS-Pfad genannt. Der XPath kann dabei helfen, er beschreibt die Position einer Information komplett ohne IDs und Klassen.
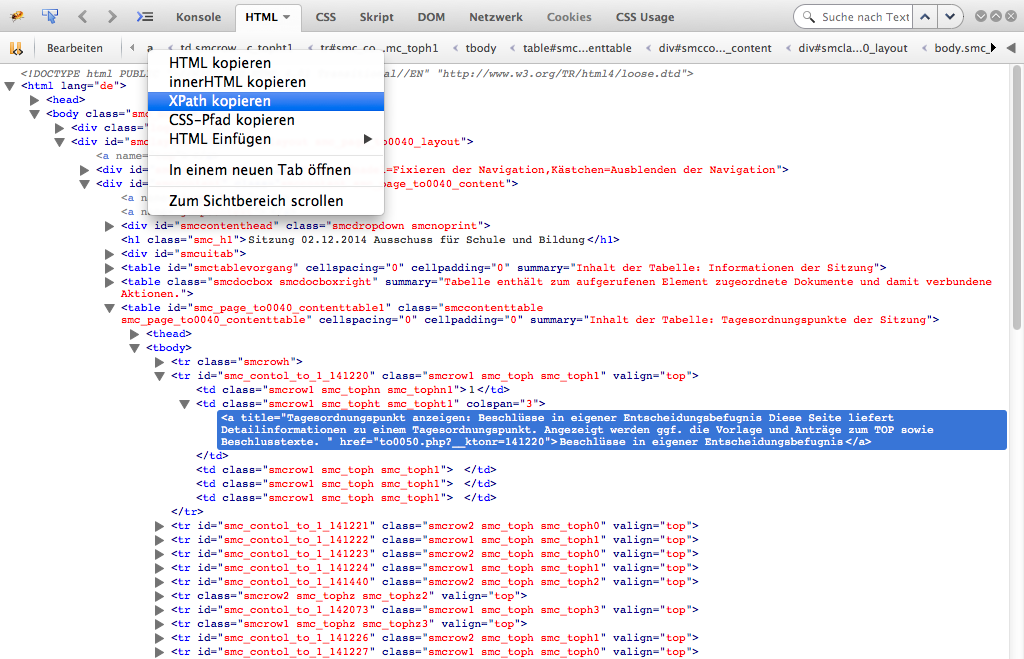
Auswählen einer Information über den XPath.
Mit dem Firefox-Plugin Firebug oder mit der Chrome Entwicklerkonsole kann man den CSS-Pfad einer Information herauskopieren. Dieser ist oftmals recht länglich:
html body.smc_body div#smclayout.smclayout.smc_page_to0040_layout div#smccontent.smccontent.smc_page_to0040_content table#smc_page_to0040_contenttable1.smccontenttable.smc_page_to0040_contenttable tbody tr#smc_contol_to_1_141220.smcrow1.smc_toph.smc_toph1 td.smcrow1.smc_topht.smc_topht1 a
Mit jedem Leerzeichen geht es eine Ebene tiefer. Das direkt nach dem Leerzeichen ist das Element, ein #id (also alles nach der Raute) ist eine ID, ein .klasse (also alles nach dem Punkt) ist eine Klasse. Der Pfad ist leider wenig universell, weil zum Beispiel smc_contol_to_1_141220 eine ID enthält, die so nie auf einer anderen Seite mit ähnlichen Informationen vorkommen wird. Dies ist dann auch die größte Herausforderung: Den CSS-Pfad so universell gestalten, dass er die gewünschten Informationen abgreift, aber eben auch nicht zu viel. Das sieht zum Beispiel so aus:
table#smc_page_to0040_contenttable1 td a
So entstehen die Selektoren, die man in der Konfiguration unter xpath findet. Dies reicht zumeist nicht komplett aus, sodass man die XPath zur Hilfe nimmt und durch die einzelnen Nodes durchspringt und in Unterbereichen des HTML-Dokuments CSS-Selektoren verwendet. Ein Beispiel dazu findet man im SessionNet Scraper: Zunächst wird das HTML als XML eingelesen (in die Variable dom). Dann testet man entweder Werte direkt mit dem Pfad auf die ganze XML (in diesem Fall sucht man sich die Überschrift h1 heraus) – oder aber man wählt sich zunächst einen Unterbereich aus (in diesem Fall alle Tabellenfelder einer bestimmten Tabelle) und verarbeitet die dort enthaltenen Infos anschließend je nach Inhalten (in diesem Fall wird der Name als Kurzname identifiziert und gespeichert).
Leider kann bei dieser Art der Informationsgewinnung so Einiges schiefgehen. Das wohl größte Problem ist, dass sich die Quelle verändert. Wenn das offizielle Ratsinformationssystem ein Update bekommt, sehen die IDs und Klassen eventuell ein ganz klein wenig anders aus – und schon funktioniert das ganze Abgreifen von Informationen nicht mehr.
Aber auch fehlende Felder können ein Problem sein: Oftmals muss man Informationen auf Basis von darüber liegenden Informationen identifizieren, also z.B. die Regel “direkt unter dem Datum folgt die Beschreibung”. Wenn aus irgendeinem Grund das Datum fehlt, schlägt auch die Identifikation der Beschreibung fehl.
Zuletzt ist auch die Menge an Code ein Problem: Auf diesem Weg ist es extrem aufwändig, Informationen abzugreifen. Man muss also für kleinste Ergebnisse viel Arbeit investieren, sodass dies unattraktiv für eine freie Entwicklerszene wird und hohe Kosten bei kommerziellen Aufträgen verursacht.
Es gibt auch einige auf Informations-Scraping spezialisierte Libraries wie Scrapy. Diese können sehr, sehr hilfreich sein, scheitern aber gerne an dem doch sehr veralteten HTML-Code von Ratsinformationssystemen, sodass ich die direkte Variante über XML- und CSS- Selektoren beibehalten habe.
Und noch etwas: Informationen, welche nur über PDF-Anhang zur Verfügung stehen, sind ein ganz besonderes Problem. Denn dort existieren nicht einmal CSS-Selektoren wie IDs und Klassen. Es ist zum Beispiel de Facto unmöglich, Tagesordnungspunkte von der Seitennummerierung zu unterscheiden, deswegen können Informationen aus PDFs nicht präzise zugeordnet werden.
Um die Suchergebnisse im offenen Ratsinformationssystem nicht allzu sehr zu verfälschen, werden daher bei der Dokumentsuche zugeordnete Tagesordnungen und Protokolle ignoriert: Es ist nicht möglich, festzustellen, ob der Suchbegriff “Baum” zum Tagesordnungspunkt 1 oder 2 gehört. Wenn die Tagesordnung Teil der Suche wäre, würde beim Suchbegriff “Baum” aber beides als Ergebnis kommen, auch wenn es in Tagesordnungspunkt 2 gar nicht um Bäume geht – die Informationen in der PDF kann man aber eben nicht trennen.
Noch schlimmer sind eingescannte PDFs. Dort muss man einen OCR-Scan drüberlaufen lassen, um den Text zu extrahieren, da er nicht direkt in der PDF steht. Dies erzeugt sehr viel Serverlast und ist sehr fehleranfällig – der OCR-Scan muss eben anhand der Bildinformationen raten, welcher Buchstabe in welcher Struktur (Satzzusammenhang, Ausrichtung, …) gemeint sein könnte. Da glücklicherweise viele (aber leider nicht alle) Dokumente der bisher bearbeiteten Städte keine Scans sind, unterstützt das offene Ratsinformationssystem diese Funktion noch nicht.
PDFs sind eben wirklich nur für den Druck richtig gut geeignet. Wenn es eine HTML-Ausgabe gibt, sollte man diese ebenfalls nutzen – damit hilft man nicht nur Programmierern.
Hin und wieder gibt es bei den bestehenden Ratsinformationssystemen XML-Schnittstellen. Diese sind zwar komplett undokumentiert, erleichtern einem das Abgreifen von Informationen aber erheblich. Außerdem sind die Schnittstellen nicht überall aktiv – vermutlich, weil man sie zum Teil dazubuchen muss, da sie eigentlich der serverseitige Teil von Smartphone-Apps sind.
Der zur Zeit nicht funktionsfähige Scraper von AllRis basiert zum Teil auf dieser XML-Schnittstelle. Teilweise, weil nicht alle Informationen über XML bereitgestellt werden – Personen, Gruppen und Gremientreffen ja, Beschlüsse / Paper aber nicht. Für den Rest verwendet man wiederum CSS-Selektoren wie in Ansatz 1 beschrieben.
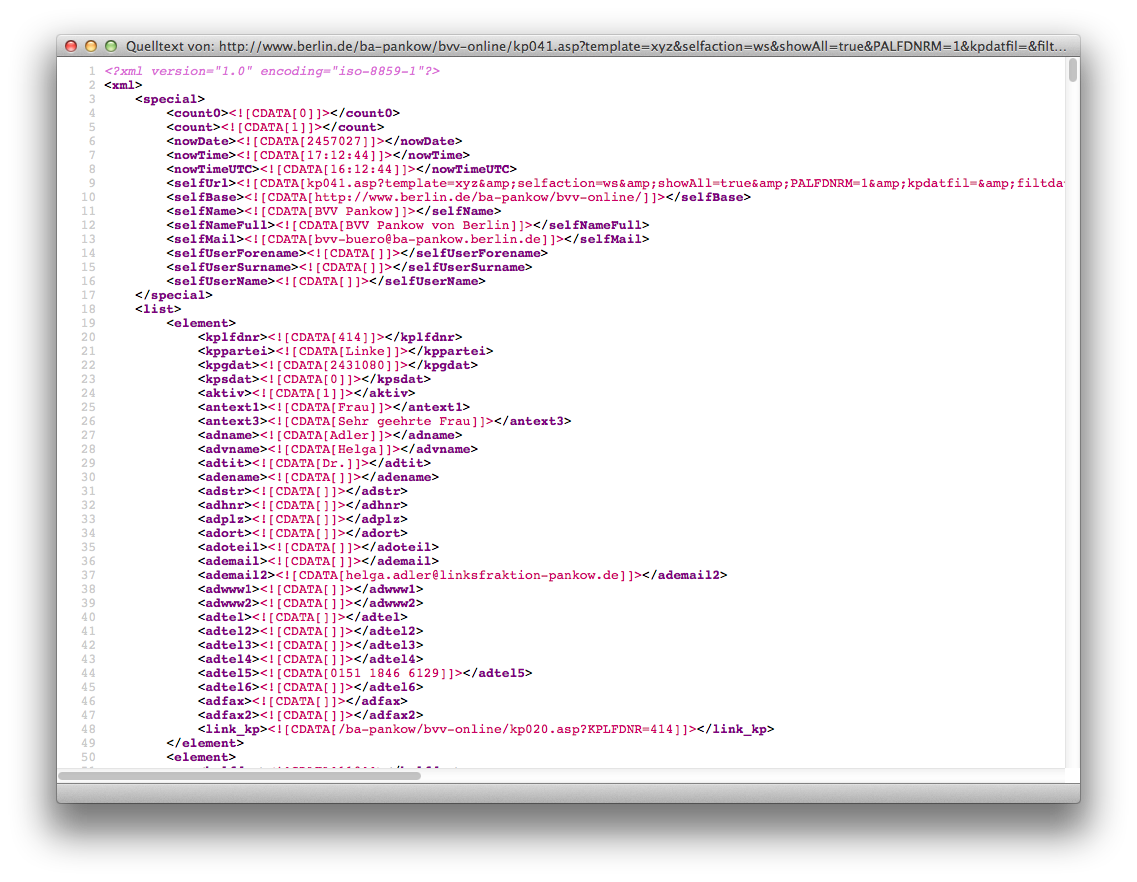
Eine typische XML-Ausgabe, hier aus dem Berliner Bezirk Pankow.
Das Bearbeiten von XML-Ausgaben besteht eigentlich vor allem aus dem Zuordnen von Informationen. Zunächst lädt man die XML-Struktur, dann springt man durch die einzelnen XML-Nodes und greift die einzelnen Informationen ab (in diesem Fall den Vornamen). Da jede Information mit einer (zum Teil kryptischen und leider nicht dokumentierten) Bezeichnung beschriftet ist, kann dabei nicht so viel schiefgehen wie bei Methode 1.
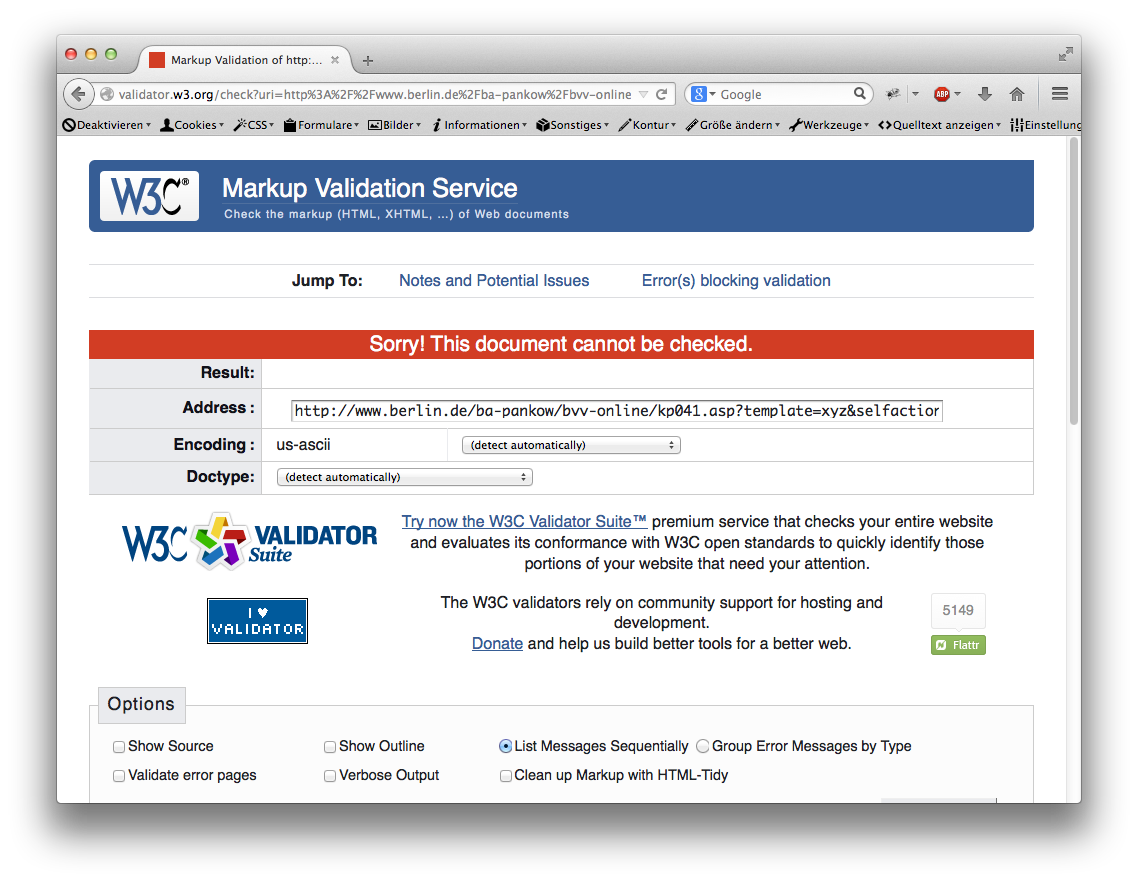
Typische Probleme mit der fehlerhaften XML-Ausgabe von Ratsinformationssystemen.
Leider ist die XML-Ausgabe oft nicht mit Hilfe von XML-Libraries entstanden, sodass die XML-Ausgabe sich nicht an den XML-Standard hält. Dies führt zu Fehlern in der Interpretation der Daten, daher ist ein sehr robuster XML-Parser nötig, um die Informationen korrekt zu interpretieren. Außerdem ist es ein Problem, dass es keine Dokumentation gibt: Die beschreibenden Strings können sich bei Updates ändern, außerdem muss man oft raten, wo sich die XML-Ausgabe versteckt, was die Parameter beim Aufruf bedeuten und welches Feld was bedeutet. Nichtsdestotrotz ist eine fehlerhafte XML-Ausgabe noch immer einfacher als Methode 1.
Oftmals fehlen wichtige Informationen in der HTML-Ausgabe. Zum Beispiel wäre es interessant, in welchem geographischen Zusammenhang ein Antrag steht. Außerdem sind ganz praktische Datenverarbeitungen sinnvoll: Das Generieren von Thumbnails, des Suchindexes, der Rohdatenexports, der XML-Sitemaps oder das Extrahieren von Texten aus PDFs. Die meisten Aufgaben davon sind recht direkt machbar, weil sie einfach nur die in der Datenbank gespeicherten Daten benötigen. Die oben angesprochenen OCR Scans gehören auch in die Kategorie Weiterverarbeitung. Die Geolokalisierung möchte ich aber genauer betrachten, weil sie das Verbinden von Daten behandelt.
Um Daten mit Geoinformationen zu versehen, benötigt man Straßennamen. Diese bekommt man bei OpenStreetMap. Dort liegen die Daten aber pro Regierungsbezirk vor – also muss man zunächst die OSM-Relation-ID nutzen, um die Straßen herauszufiltern, welche tatsächlich zu der Stadt gehören. Dies geschieht über den OSM-Import. Dieser speichert die Straßennamen in die MongoDB ab.
Das Script generate_georeferences.py nimmt dann beide Datenquellen – Ratsinformationssystemdaten plus OSM-Daten – und matcht diese miteinander. Im Einzelnen: Zunächst lädt es alle Straßennamen, generiert Abwandlungen wie Abkürzungen und schaut anschließend, ob eine der Namen in den Textexporten der Anhänge vorkommt.
Ich hoffe, dass man mit diesem kleinen Artikel einen Einblick in die Gewinnung von strukturierten Informationen bekommen hat. Wer Lust hat, sich damit intensiver zu beschäftigen – der Scraper für Ratsinformationssysteme freut sich über Patches!
Moers war lange Zeit die einzige Stadt, welche im Ruhrgebiet offene Daten angeboten hat (und so richtig glücklich ist Moers bei dieser Zuordnung ja auch nicht und bevorzugen den Niederrhein 😉 ). Mit dieser Woche hat sich das auf jeden Fall geändert: Bochum wurde NRWs OpenData Stadt Nr. 6.
Die Presseeinladung dazu war fast ein wenig unscheinbar, präsentiert wurde das neue Angebot auf der regelmäßigen montäglichen Pressekonferenz der Stadt. Aber statt nur ein paar Ankündigen was gemacht werden könnte wurden Ergebnisse präsentiert. Die wichtigsten Änderungen dürfte eine übersichtliche Sammlung aller Online-Dienste auf einer Seite sein (welche man sonst nie gefunden hätte) – und ein OpenData Portal mit 22 Datensätzen für den Start.
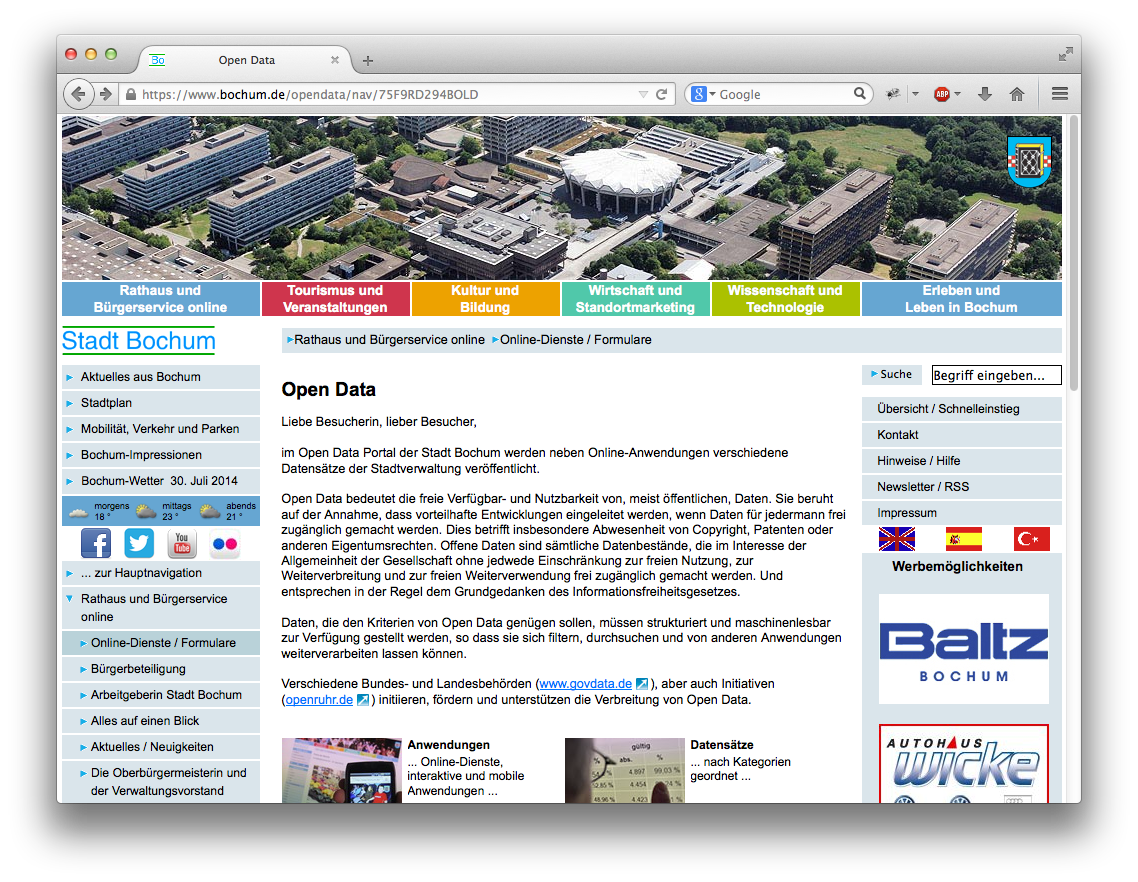
OpenData Portal Bochum
Das Thema begleitet die Stadt scheinbar schon seit etwa zwei Jahren, und auch der Start von OpenRuhr:RIS schien nicht unbeachtet geblieben zu sein. Der Platz 24 bei dem Ranking Online-Angebote aller NRW-Kommunen initiiert von der Grünen Landtagsfraktion (bei der OpenRuhr und die OKF als Experte herangezogen wurde) hat dann wohl endgültig das dafür gesorgt dass man zeigen wollte: Bochum kann mehr. Ein knappes halbes Jahr später gibt es nun die Ergebnisse.
Bemerkenswert ist auch die Situation unter der die Datensätze gesammelt wurden. Bochum hat finanziell die eine oder andere Schwierigkeit zu meistern, so dass es aktuell (wieder) in der Haushaltssperre ist. Unter diesen Voraussetzungen das Thema OpenData zu bearbeiten zeigt, dass offene Daten nicht viel Geld kosten müssen. Bemerkenswert ist auch die sehr pragmatische Herangehensweise des Angebotes: die Initiative kommt aus der Verwaltung, und zunächst nutzt man das stadteigene CMS, um die Daten bereitzustellen – beides aus er “OpenData-Stadt” Moers bekannte Strategien.
Auf der Pressekonferenz haben die Vertreter der Stadt dazu aufgefordert, dass sie gerne weitere Daten bereitstellen würden, wenn die Community sagt, was sie haben möchte. Und natürlich freut sich die Stadt über Anwendungen, die auf Basis ihrer Daten entstehen.
Was schon fest geplant ist ist eine Mängelmelder-App, mit welcher dann mobil mit der GPS Position des Smartphones Daten eingereicht werden können. Dies scheitert zur Zeit an der Haushaltssperre, womit die dafür benötigten 8.000 € nicht freigegeben werden können. Auch ein öffentliches Tracking der Anliegen ist denkbar, aber auch dafür wird Geld benötigt, da dies das Stadt-CMS so nicht hergibt.
Wir als OpenRuhr würden uns sehr freuen, wenn aus den Daten spannende Apps entstehen würden – dieses Blog dient dann auch gerne zur Vorstellung. Bislang eignen sich die Daten für Karten-Visualisierungen, aber je mehr Datensätze bereitgestellt, desto eher lassen sich da auch Daten verknüpfen.
UPDATE: Für die erste Inspiration sammeln wir in einem Etherpad weitere interessante Datensätze, die wir dann der Stadt Bochum übergeben. Ziel sollte v.a. sein, dass dann am Ende auch tatsächlich Anwendungen auf Basis dieser Daten geschaffen werden können.
Die bei OpenRuhr:RIS verwendete Software ist zwar OpenSource-Software, wirkt auf dem ersten Blick aber etwas unübersichtlich, was sicherlich die Mithilfe an dem Projekt schwieriger macht. Dies dürfte unter anderem auch an den verwendeten Komponenten liegen, Flask, MongoDB und ElasticSearch gehören nicht unbedingt zu dem, womit man täglich arbeitet.
Doch so schwer ist es nun auch nicht, wie es auf dem ersten Blick auszusehen scheint. Um das zu verdeutlichen und den Einstieg in die Entwicklung von OpenRuhr:RIS zu erleichtern haben wir eine Virtuelle Maschine für VBox zusammengestellt, mit dem man leicht die ersten Schritte gehen kann.
Mit dieser virtuellen Maschine hat man eine fertige Installation von Scraper und Weboberfläche. Die Monate Januar bis März 2013 der Stadt Bochum sind dort bereits gescraped, d.h. man kann innerhalb von Minuten eine eigene OpenRuhr:RIS Instanz auf seinem lokalen Computer starten und das System Schritt für Schritt entdecken.
Um die virtuelle Maschine zu starten benötigt man die kostenlose Virtualisierungssoftware VirtualBox, welche für Windows, Linux, Mac OS-X und Solaris zur Verfügung steht. Außerdem benötigt man den gut 4 GB großen Download der virtuellen Maschine mit OpenRuhr:RIS. Um die virtuelle Maschine nutzen zu können sollte man einen Rechner mit 4 GB RAM oder mehr haben sowie 40 GB Festplattenspeicher übrig haben.
Zur Vorbereitung müssen wir VirtualBox installieren und die heruntergeladene virtuelle Maschine entpacken (z.B. mit 7Zip). Doppelklickt man nun auf RIS.vbox, wird die virtuelle Maschine zu VirtualBox hinzugefügt. Nun sollte man noch das Netzwerk konfigurieren (Ändern -> Netzwerk), dort wäre Netzwerkbrücke (alternativ: NAT) empfehlenswert, um eine Internetverbindung zu bekommen und ggf. Zeroconf nutzen zu können.
Nun können wir die virtuelle Maschine starten und uns in die Ubuntu 12.04 Server-Installation einloggen (Nutzer: ris, Passwort: ris). Mit sudo -i (Passwort: ris) erhalten wir dann eine Root-Shell.
Die Weboberfläche
Schauen wir uns als erstes die fertige Installation der Weboberfläche mit den bereits bestehenden Daten an. Dazu wechseln wir mit sudo -i -u ris-web in den Nutzer ris-web und wechseln dann mit cd /opt/ris-web/ in das Arbeitsverzeichnis der Weboberfläche. Dort angekommen aktivieren wir mit source ris-web/bin/activate das virtuelle Python-Enviroment für die Weboberfläche.
In der aktuellen Version der Weboberfläche müssen wir nun noch den Hostname anpassen. Dieser sollte unserer IP-Adresse mit Port 5000 gleichen. Mit ifconfig eth0 kriegen wir unsere aktuelle IP der virtuellen Maschine heraus. Diese tragen wir mit vim city/bochum.py bei dem Wert BASE_URL ein (also z.B. http://192.168.0.100:5000/ ).
Nun ist die OpenRuhr:RIS Weboberfläche startbereit: mit python runserver.py starten wir die Oberfläche. Nun können wir unter der IP-Adresse mit Port 5000 (also wie in BASE_URL, z.B. http://192.168.0.100:5000/ )in einem Browser die Oberfläche anschauen, Suchen, Details betrachten, … etc. Voilà!
Der Scraper
Auch der Scraper ist in der virtuellen Maschine startbereit. Dafür beenden wir die Session vom Nutzer ris-web und starten mit sudo -i -u ris-scraper eine Session für den Nutzer des Scrapers. Mit cd /opt/ris-scraper wechseln wir in das Arbeitsverzeichnis des Scrapers, mit source ris-scraper/bin/activate aktivieren wir das virtuelle Python-Enviroment. Der Scraper ist nun einsatzbereit.
Um nun z.B. die Monate April bis Juni zu den bestehenden Daten hinzuzufügen starten wir den Scraper mit folgenden Parametern: python main.py -v -q –start 2013-04 –end 2013-036 . Achtung – das wird ein paar Stunden dauern, bis der Scraper fertig ist! Alle weiteren Möglichkeiten gibt es in der Dokumentation / Readme des Scrapers zu lesen.
Aktualisieren der OpenRuhr:RIS Software
Die Aktualisierung ist recht einfach, da OpenRuhr:RIS wie auch sein Vorbild offeneskoln.de in Github entwickelt werden. Gehen wir von einer Root-Konsole aus, wechseln wir mit sudo -i -u ris-web und cd /opt/ris-web in den richtigen Nutzer und das richtige Arbeitsverzeichnis. Nun können wir ganz einfach mit git pull die neusten Updates vom OpenRuhr Git Repository bekommen. Das Ganze funktioniert natürlich auch analog mit ris-scraper.
Nächste Schritte: Entdecken und selbst anpassen
Mit der OpenRuhr:RIS virtuellen Maschine habt ihr die Basis, mit der ihr selbst anfangen könnt, das System zu entdecken und anzupassen. Besonders interessant dürften Anpassungen an den Scraper sein, da man dadurch andere Städte mit einem offenen Ratsinformationssystem ausstatten kann.
Wenn jemand dabei einen funktionierenden Scraper für eine weitere Stadt im Ruhrgebiet entwickelt kann er sich gerne bei uns melden: wir kümmern uns dann um das Hosting. Die VM selbst ist nicht für die Bereitstellung im Netz gedacht, sie hat an vielen stellen eine sehr unsichere Konfiguration, die die Entwicklung sehr komfortabel macht, aber nicht für den Produktiveinsatz geeignet ist.
Für Fragen kommentiert gerne diesen Post oder meldet Euch auf der RIS-Entwicklungs-Mailingliste des OKFN.
Bei der Veröffentlichung des alternativen Ratsinformationssystems OpenRuhr:RIS vor einem Monat für Bochum und Moers war von Anfang an mehr geplant: die schrittweise Ausweitung das Thema OpenData in das ganze Ruhrgebiet. Den ersten Schritt dazu machen wir heute: das alternative Ratsinformationssystem OpenRuhr:RIS:Duisburg wird ab sofort unter http://duisburg.ris.openruhr.de/ abzurufen sein.
Außerdem haben wir ein neues Feedback-System für Anhänge freigeschaltet, um Probleme mit diesen direkt melden zu können. Ebenfalls sind nun Datenbank- und Anhang-Downloads ab sofort tagesaktuell. Viel Spaß bei der Nutzung des Systems!
Wenn Du OpenRuhr:RIS auch in Deiner Stadt haben möchtest und / oder Lust hast, an dem Projekt mitzuwirken melde Dich bei uns! Von Python- und JavaScript-Programmierern über OpenData-Bloggern bis hin zu politisch Aktiven mit direktem Draht in die Städte können wir in allen Bereichen Unterstützung brauchen – wir freuen uns auf Deine Mitwirkung.
Anbei noch die Pressemitteilung, die an Pressevertreter aus Duisburg und dem Ruhrgebiet verschickt wird:
Duisburg, 01.08.2013: Alternative Ratssysteme sorgen für mehr Transparenz der Stadt, macht Politik sichtbarer, Mitbestimmung leichter und zeigt zivilgesellschaftliches Engagement. Ein solches System wurde heute für Duisburg veröffentlicht ( http://duisburg.ris.openruhr.de/ ) . Die Plattform ist eine Weiterentwicklung der zuvor von OpenRuhr veröffentlichten alternativen Ratsinformationssystemen Bochum und Moers sowie des viel beachteten Projektes offeneskoeln.de. Mehr Infos auf dem OpenRuhr Blog: https://openruhr.de/
Mehr politische Sichtbarkeit, mehr Transparenz, mehr Informationen für Beteiligung: das soll die zentrale Kommunikationsplattform des Rates, das Ratsinformationssystem, leisten. Doch die Nutzung ist für Bürgerinnen und Bürger oft schwierig, da die Systeme für die täglich damit arbeitenden Rats- und Verwaltungsmitglieder optimiert sind. Doch die Informationsbedürfnisse der Bürgerinnen und Bürger kommen häufig zu kurz. Daten, welche als Offene Daten unter freien Lizenzen angeboten werden, schaffen einen guten Nährboden für mehr Demokratie und Mitbestimmung, aber auch für innovative Wirtschaft.
Ein Fokus auf die Bürgerinnen und Bürger: das haben wir nach Bochum und Moers[1] nun für Duisburg realisiert – basierend auf den Daten der Orginal-Ratsinformationssysteme[2]. Wir, das ist OpenRuhr, eine im März 2013 gegründete Initiative von OpenData-Enthusiasten, die in ihrer Freizeit mehr Demokratie möglich machen wollen. Und wir möchten Sie einladen, sich unser neues Ratsinformationssystem OpenRuhr:RIS:Duisburg einmal anzuschauen und gerne damit im Alltag zu arbeiten sowie Rückmeldungen zu geben: http://duisburg.ris.openruhr.de/.
“Damit das Ruhrgebiet hier eine Vorreiterrolle einnehmen kann, werden wir in Folge diesen Service auf weitere Ruhrgebietsstädte ausweiten und weitere Gespräche zu mehr OpenData im Ruhrgebiet führen. Duisburg ist hier der erste Schritt der versprochenen Ausweitung, es werden noch viele weitere folgen.”, so Ernesto Ruge, Initiator der Initiative OpenRuhr.
OpenRuhr:RIS ist ein Projekt des Open Knowledge Foundation Deutschland e.V.[3], welcher sich bundesweit für die Öffnung von Wissen, Open Data und Open Goverment engagiert. Vorbild für OpenRuhr ist Marian Steinbachs offeneskoeln.de[4]. Unser Angebot ist dank der Unterstützung des Linuxhotels [5] kostenlos und werbefrei. Inzwischen hat die Stadt Moers über OpenRuhr:RIS hinaus als eine der ersten Städte in NRW ein OpenData Portal lanciert und steht damit im Zentrum des Interesses zahlreicher Organisationen. Parallel dazu bereitet das Land NRW zur Zeit mit OpenNRW [6] ein großes OpenData Portal über alle Ministerien hinweg geplant.
Initiative OpenRuhr
(Presse-)Kontakt: Ernesto Ruge, info@openruhr.de, 0173 166 21 74, https://openruhr.de/
[1] https://openruhr.de/2013/06/20/openruhrris-wurde-veroeffentlicht/
[2] Bürgerinformationssystem der Stadt Duisburg: https://www.duisburg.de/ratsinformationssystem/bi/
[3] Der Open Knowledge Foundation Deutschland e.V. ist ein gemeinnütziger Verein in Berlin, der sich für die Verbreitung von freiem und offen zugänglichem Wissen in der Gesellschaft einsetzt: http://okfn.de/about/
[4] offeneskoeln.de sammelt und bereitet Dokumente und Daten auf, die im Ratsinformationssystem (RIS) der Stadt Köln veröffentlicht werden, und stellt sie in einer nutzerfreundlichen Art und Weise dar: http://offeneskoeln.de/ueber/
[5] Das Linuxhotel in Essen ist ein auf Open-Source Software spezialisiertes Schulungsunternehmen: http://www.linuxhotel.de
[6] Open.NRW: das Landeskabinett hat die ressortübergreifende Projektgruppe „Open.NRW“ mit der Erarbeitung einer Open-Data Strategie für das Land NRW beauftragt.
Nach der Veröffentlichung von Bochum und Moers bekommt nun die dritte Stadt im Ruhrgebiet ein offenes Ratsinformationssystem: das alternative Ratsinformationssystem OpenRuhr:RIS für die Stadt Duisburg wird am 1.8.13 online gehen.

Außerdem wurde ein neues System für Rückmeldungen von Anhängen online geschaltet. Jeder Nutzer kann so Urheberrechtsverletzungen, nicht lesbare Anhänge oder fehlerhaft in bei Suchbegriffen auftretende Ergebnisse melden. Die Rückmelde-Buttons befinden sich direkt neben den Anhängen.
Du möchtest OpenRuhr:RIS auch für Deine Stadt? Du möchtest mithelfen? Gerne – melde Dich bei uns oder melde Dich direkt bei der OKFN Entwickler-Mailingliste an!
Das Projekt OpenRuhr:RIS, das alternative Ratsinformationssystem für das Ruhrgebiet, hat es auf das Blog netzpolitik.org geschafft. In dem Artikel haben wir die aktuelle Entwicklungen aufgezeigt, die neuen Veröffentlichungen präsentiert und zu Mitarbeit aufgerufen. Wir wünschen viel Spaß beim Lesen!
Wir haben mehrere Städte bereits jetzt in Vorbereitung. Aber um OpenRuhr:RIS auf weitere Städte zu erweitern, brauchen wir Deine Hilfe. Ganz konkret brauchen wir neue Scraper, welche zur Zeit in Python entwickelt wurde. Interessierte Programmierer können sich gern auf der OKFN Mailingliste melden. Aber auch nicht-IT-affine Menschen werden gesucht, wenn OpenData bedeutet auch viel Informationsvermittlung, aber auch Planung von einem demnächst stattfindenden Hackday. Melde Dich gerne bei unserer Mailingliste an oder melde Dich direkt unter info@openruhr.de.